




Until last night I really didn't understand hash tables. I've watched videos and read about them computer science textbooks, but some part of my brain always said "this is confusing and not something I really need to understand.... too many words ... too many weird terms.... ignore for now". I’m pretty sure I vaguely (and wrongly) thought the items themselves were split apart into chunks and somehow distributed throughout a structure. So I decided it was finally time to dig in and figure it out, and as in my previous posts in this series studying computer science concepts by coding, the best way to learn it to actually write some code. This blog is not intended to help you have your own hashmap epiphany; instead it will serve as a way for me to document my thought process and code implementation in hopes it might assist both of us in learning.
Some Terminology
Understanding a new concept is often frustrating as the resources you reference might include unfamiliar terminology. Even worse are the circular definitions where they “explain” one term you don’t know by using 3 other terms you also have never heard of. Here is a brief run down of the key elements of a hash map and how they relate to one another:
- Hash (Hash Function): a process of converting an item (or value) into a key (or location index) in a predictable way; in this case determining a table location based on some property of the item that needs to be stored there
- Hash Map: a data structure that stores items efficiently by using a hash function to determine items locations
- Hash Table: an implementation of a Hash Map that specifically uses a table-like structure (as opposed to another type of data structure)
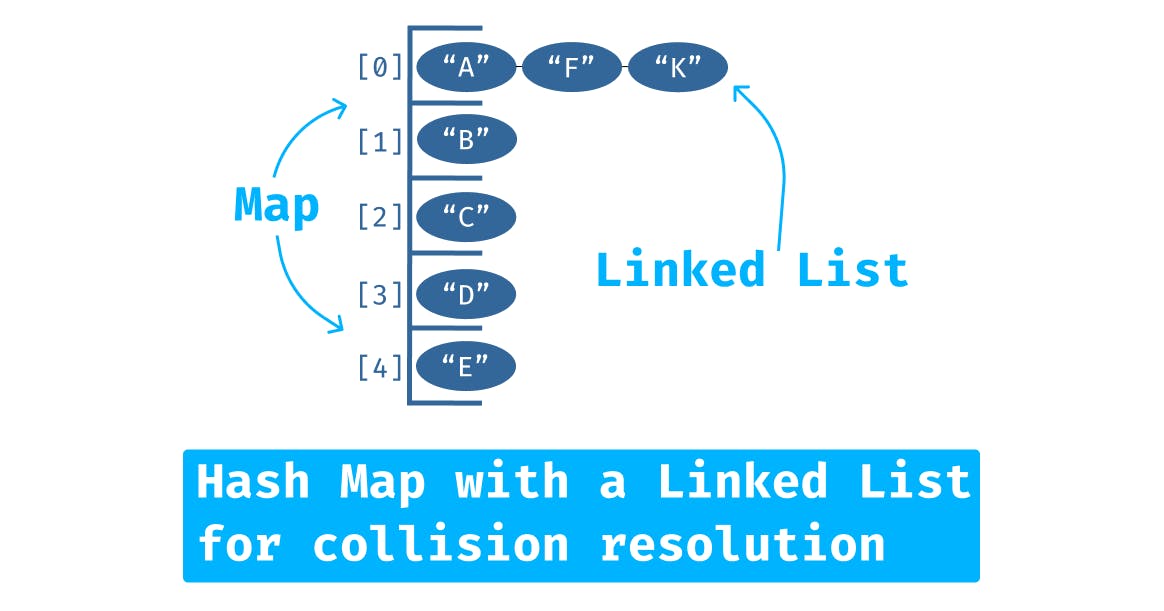
- Collision: when your Hash function assigns the same location to multiple items
- Probing: one way of resolving a collision: iterate through the rest of your table (looping around to the beginning if needed) until you find a new, open location for the item that caused the collision
- Chaining: another way of resolving a collision; insert the new colliding item into the location along with the existing item(s), and chain them together using a linked list or similar sub-structure
Getting Started
I personally start these computer science coding exercises the same way I start my web application projects: by writing my user stories. What exactly will I, as a user of this data structure, want it to do? Once I have these stories in place, I start to determine what classes I might use to best represent the entities involved. Then, it's a matter of creating methods for the relevant classes that will allow me, as a user, to interact with this object. The final step is creating a test program that can instantiate this class and test its functionality by walking through the execution of each user story. I look forward to learning more about Jest, PyTest, and other similar automated testing tools to improve this part of my process.
User Stories
These are the basic things someone would want a hash map to do:
- accept a value and store it using a hash function
- inform you whether a value is present in the map or not
- remove a particular value from the map (if it is present)
Classes
The classes I used in my implementation were pretty limited:
Hash_Map()Stack()- in a previous blog post, I had created a stack structure utilizing a linked list. It needed some updates, but worked well for resolving collisions using chainingNode- I had already created this class when creating the stack with linked list implementation, and didn't even need to touch it for this exercise. Modularity!
Functionality
Brainstorming
I find it helpful to sketch out all of the functionality I can think of that might be needed for each user story. Sometimes it's 1-to-1, but often a story might contain several steps that can be broken down. In my case, all of these functions will technically be methods since they will exist as properties of the classes I defined above. Some of these class methods will be public and accessible directly by the user, while others will be private and simply accessed internally by other class methods.
To start, I often just create empty placeholder functions which log their own name:
def hash(self, value):
# placeholder method - but this will eventually do something cool!
print(f'Hash')
return
When I start to flesh out those functions, I'll write out the steps in #comments to visualize my logic flow. Another helpful step is to log any passed arguments with some descriptive text: print(f'Hash(): hashing {value}"). Once these are logging properly, it will be much easier to isolate future errors as being in the business logic rather than in the routing or setup.
Class Methods of Hash_Map()
Public Methods
(called by the user in our test.py or any implementation program)
insert()- User Story #1. Accepts an item, hashes to calculate the key, and places the item in the structure (in my code, a list withinHash_Mapcalled referenced withself.table)search()- User Story #2. Accepts an item, and returns a Boolean (TrueorFalse) indicating whether the item was found in the hash map.remove()- User Story #3. Accepts an item which it removes and returns if found, otherwise returnsFalse
Internal Methods
(called from other methods within the same instantiated class)
get_hash()- take an item and calculate a key or table index based on the item's value(s).Python Note:
hashis already a keyword in Python so don't try and name this methodhash()as I initially did; it was causing some very strange errors until I realized my mistake__str__()- this is a special method in Python, referred to as a "dunder" method (double-underscores), and will allow you to add a customized response when your object is converted to a string (usingprint(object)orstr(object)in the test code for example). Normal Python behavior for objects of instantiated classes would be to return a memory address, but we would like to return a formatted string so we can actually view our beautiful new hash map!
Class Methods of Stack()
Since our Hash_Map class will rely on inner linked lists (to resolve collisions), we will load up a previously written stack with a linked list module using from linked_list_stack import Stack. We can eliminate some of the methods from Stack as they won't be needed, e.g. reverse(), to_list(), and peek().
We will also need to add some additional methods to complete the user stories' search() and remove() methods, specifically those in table locations that are storing more than one item. So Hash_Map.search() will find the correct location on the table where the item should be, but Stack.contains() will then check every item stored at that particular location's Stack for a match.
Note: I decided to implement a Stack() on every table location, regardless of the number items at that location. This may be inefficient; I'll continue my studying and see if it's better practice to store an item "naked" at first, and then place the naked item and any new items into a linked list only as needed to resolve collisions.
Public Methods
(called from within Hash_Map)
push()- classic stack behavior which plops the value on top of the stack. This continues the work ofHash_Map.insert()in my codecontains()- walks node by node through the particular stack looking for a match.remove()- similar tocontains()in that it walks through the stack checking for a match (and then removing it if found). However, the implementation gets a bit trickier; first, you must check your match against the next node in line, not the current, since to remove the current you'll need to connect the previous node to the next. This is very similar to the idea of "don't drop your rope" I discussed in Reverse a Stack with Python; you need to take care not to lose track of your previous and next nodes as those are the connections that hold the chain together__str__(): similar to the special method within our hash map class, we need a custom method when an instance of our stack is converted to a string
Note: as in our Snake Tac Toe game; it's very easy as a beginner to get tripped up by referring to an instantiated object, when you really meant to refer to a particular property of that object. Here, in both
contains()andremove(), we need to compare the search item (a string) to the string value of each particular node, not to the node itself. In my code there are two ways I do this, the first is by calling.valueon the node, other places I usestr(node), which internally calls the special__str__()method we added. Either way, you must be sure you are comparing values of the same type. You can confirm a variable's type by logging:print(type(a_variable))and seeing what you are actually dealing with.
def contains(self, item):
current_head = self.head
while current_head != None:
# 👎This won't work 👎
# if current_head == item: return True
if current_head.value == item: return True
# 👍 But this will! 👍
current_head = current_head.next
return False
Testing our Hash Map
I try to keep my class definitions in their own .py files when possible. They can easily be imported into other files and scripts as needed. For this project, I am using 3 files:
hash_table.py- contains our new hash map class, utilizing a table full of stacks internallylinked_list_stack.py- contains ourStackclass and the very simpleNodeclass, which is used to create the links in our linked list stacktest.py- starts with some arbitrary data; instantiates an object of classHash_Map(); then adds, finds and removes various data from that structure
To import one file into another, you can just use the import statement (as opposed to JavaScript where you must also explicitly export within the file to be imported).
Performance and Big O()
A rule of thumb recommendation is to make your table about 30% larger than your data set when hash mapping; this helps to minimize wasted resources by having the table too large and with lots of empty locations or too small and resulting in many collisions. We therefor send in the TABLE_SIZE as a calculated argument using this line: TABLE_SIZE = int(len(data) * 1.3)
A properly hashed table should be nearly as fast as a basic array, since the values are mostly a single lookup. This means the time complexity would be BigO(1) for arrays, and also for absolute best-case hash maps. However, if the table you choose is too small, there will be more collisions (multiple items overlapping and stored in the same locations). Our insert() method still will be BigO(1) since it's just the single operation to get to the correct location and the second operation to push our item on to the top of that stack. Retrieving and deleting that item though could require walking through every item within a particular stack. It's possible that every item we need to store could somehow end up in the same table location, meaning our hash map is really just one giant linked list. In this worst-case scenario, our hash map would have BigO(n), since it would walk through every single item we added to the structure.
More To Come...
Overall, this implementation is very simple, as my goal was really to just to get it working. The hash algorithm I chose is not very sophisticated; it tallies the ascii value of a string's characters and then chops the sum down until that number fits inside the table. There are many other hash methods, which can optimize performance and minimize required space in memory. I'm excited to have this basic version up and going, and a more complete mental model of what is happening. I plan to continue implementing these data structures and algorithms in the languages I'm learning, and would love to hear from you if you have any comments, corrections or feedback. Thanks for reading!
To view the code or suggest changes, visit the GitHub repo.
Photo in cover image by Jan Baborák on Unsplash